前言
生活在網際網路以及智慧型手機普及的今天,與外國朋友聊天、出國旅行、與國外客戶開商務會議,縱使不熟悉當地語言,只要開啟Google Translate,語言的隔閡立馬迎刃而解。幾年前大家還在詬病Google小姐翻譯出來的文句十分生硬,只要句子一長就可能翻譯出令人啼笑皆非的結果。然而在加入了類神經網絡(artificial neural network)的架構之後,翻譯品質大幅提升,產出的句子更像「人話」了。類神經網絡究竟以什麼方法改善了翻譯精準度?就讓我用這三十天,從自然語言處理基礎到加入深度學習的實務應用,一窺這項傲人技術的真實面貌。
自然語言處理
一、自然語言?非自然語言?
自然語言指的是人類日常生活賴以交流的語言和文字,像是我們所使用的中文、英文、日文等等,其活動包含了「聽」、「說」、「讀」、「寫」四個層面。為了與人工建構的編程語言做出區別,而被冠上了「自然」二字。
二、什麼是自然語言處理?
自然語言處理(natural language processing, NLP)指的是讓電腦理解、詮釋以及操作人類語言文本的技術,結合了電腦科學、語言學以及人工智慧。

圖片來源:https://algorithmxlab.com/blog/natural-language-processing/
單純的自然語言處理專注在「讀」、「寫」兩個範疇,僅處理文本資訊;廣義的自然語言處理還包含了「聽」、「說」將語音訊號處理的技術等。我們可以將這整個偌大的學門區分為機器理解人類語言(natural language understanding)以及生成文本(natural language generation)兩大階段性任務。前者例如辨識文字訊息當中有無不雅字詞、判斷一篇文章是令人愉悅的或鬱悶的等等感知的過程;而後者則像是聊天機器人如何針對使用者輸入的訊息做出流暢且合理的對答。
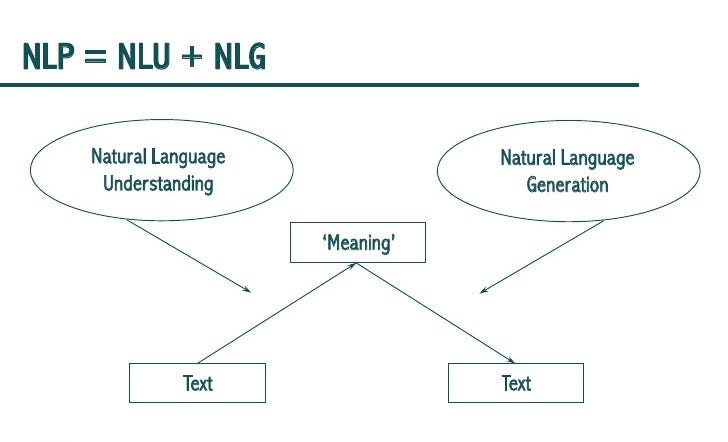
圖片來源:https://towardsdatascience.com/nlp-vs-nlu-vs-nlg-know-what-you-are-trying-to-achieve-nlp-engine-part-1-1487a2c8b696
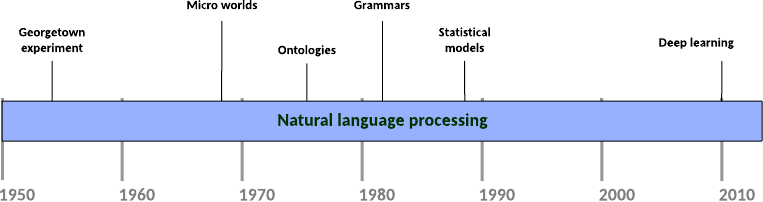
自然語言處理並非一項新創的技術或概念,早在1950年代,被譽為電腦科學與人工智慧之父的Alan Turing就提出了著名的圖靈測試(又稱模仿遊戲)來測試機器是否能夠幾乎與人類無差別地以文字為溝通管道進行交流,以此來測試機器是否有思考的能力。
綜觀自然語言處理的發展,大略經歷了三個時期:
-
規則時期(1950年代-1990年代早期):藉由文法規則和語言模式,將所有可能的文本信息以if-then邏輯進行程式設計,讓機器做出回應,是一種基於規則的方法(rule-based NLP)。第一部聊天機器人ELIZA就是以此手法創造出來的。由於此設計手法是決定性的(deterministic),加上要應付真實世界人類語言文本信息的可能性太多,需要寫入的條件判斷規則就愈大量,系統也會變得相當複雜。
-
統計方法時期(1990年代-2010年代):由於電腦計算效能的提升,人們逐步擺脫了手刻規則的枷鎖。傳統機器學習(有別於基於神經網路架構的深度學習)演算法協助電腦在龐大的語料庫(text corpus)中「找尋」語言的文法規則,以機率的形式預測結果,而非給出單一結論,從而實現從樣本(電腦中存有的文本資料)推斷母體(真實世界的所有語境)特徵的推論統計(statistical inference)。舉例來說,基於機率論中馬可夫模型(Markov model)計算文本中連續出現的N個語詞頻度的N元語法(N-gram model)被運用來建構翻譯器;監督式學習(supervised learning)範疇裡的決策樹(decision tree)、K-近鄰演算法(k-nearest neighbours, kNN)以及單純貝氏分類器(naive Bayes classifier)等演算法被運用來判別一段文字訊息是正向、負向或是中性的情境分析(sentiment anaylsis)。
-
深度學習時期(2013-現在):類神經網路能做到自動擷取資料特徵,克服了傳統機器學習需要仰賴人工進行特徵工程的缺點。循環神經網絡(recurrent neural network, RNN)具有記憶歷史資訊的特性,在處理有先後順序性的文字訊息時具有強大的優勢。本系列後半部分將著重在此範疇,在此就不贅述。
圖片來源:https://developer.ibm.com/articles/cc-cognitive-natural-language-processing/
三、自然語言處理的常見任務
我們可以大致依照問題的難易程度列出主要的處理課題:
- 文本校正(text correction):檢查拼字錯誤、文法錯誤,實例如Grammarly的Grammar Check
- 信息檢索(information retrieval, IR):從大量文本集合中找尋特定資訊,例如網站或圖書館的搜尋引擎
- 主題建模(topic modelling):從文本或語料庫中發掘出潛在的主題,是為一種非監督式的機器學習(unsupervised learning)
- 文本分類(text classification):顧名思義就是將文本分類,應用如情感分析、垃圾郵件過濾等
- 資訊抽取(information extraction):從非結構化文字資料來源中擷取出特定資訊,例如地名、人名等專有名詞,加以分辨,以存取到資料庫的過程
- 文本摘要(text summarisation):將大篇幅的文章濃縮成簡短的金句,依照直接與間接從文本擷取資訊,又分為提取式(extractive)和抽象型(abstractive)
- 問答系統(question answering):以口語化的方式進行提問,機器則回傳明確的答案,例如IBM開發的華生系統
- 機器翻譯(machine translation):藉由程式將一語言轉換為另一語言的技術,例如我們熟知的Google Translate、Microsoft Bing Translator等
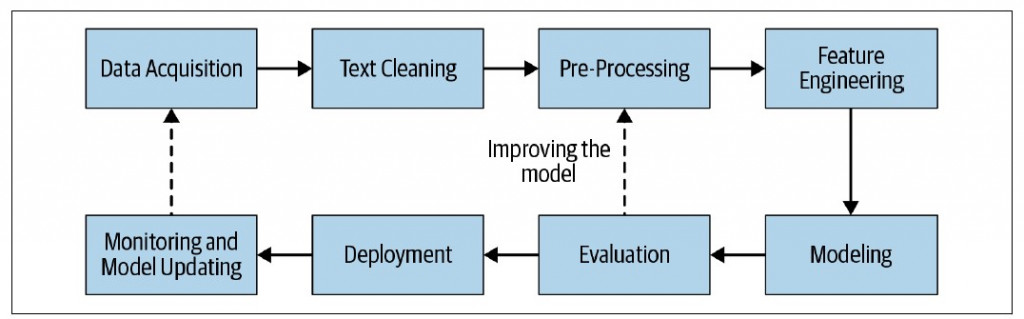
四、自然語言處理的基本流程
現今自然語言處理系統仰賴數據,以機器學習(包含深度學習)的模式進行運作。主要流程為:
- 資料擷取
- 資料淨化
- 資料前處理
- 特徵工程(類神經網絡則自動化此步驟)
- 建模
- 模型評估
- 模型佈署
- 效果監控及模型升級
圖片來源:Practical Natural Language Processing by S. Vajjala et. al
本系列篇章安排
| 日期 |
主題 |
| 01 |
序章:自然語言處理初探 |
| 02 ~ 07 |
自然語言處理基礎 |
| 08 ~ 15 |
常見的自然語言處理技術 |
| 16 |
深度學習回顧 |
| 17 ~ 29 |
神經機器翻譯理論與實作 |
| 30 |
總結與未來展望 |
之所以選定這個主題,是基於自己對於語言學及人工智慧興趣的結合。身為初次正式接觸自然語言處理的我,接下來一個月的時光,將會將自己一路上所學到的重點整理成文章並每天更新。表達有誤之處,還希望能不吝指正。今天的篇章就寫到這裡,我們明天見!
閱讀更多
-
How Google is using emerging AI techniques to improve language translation quality
-
Google Neural Machine Learning
-
Using Decision Trees to Classfiy Text
-
Common NLP Tasks

